
文章摘要
Shenandoah是低停顿时间的垃圾收集器,通过与正在运行的Java程序并发地执行更多垃圾收集工作来缩短GC停顿时间。Shenandoah并发地完成大部分GC工作,包括并发整理,这意味着它的停顿时间不再与堆的大小成正比。收集200GB堆或2GB堆的垃圾应具有类似的低停顿行为。
本文对Shenandoah GC官方文档进行简单翻译,方便对该垃圾收集器的使用,原文参见: Shenandoah wiki page。
[TOC]
综述
Shenandoah是区域化的收集器,它将堆保持为region集合。
常规的Shenandoah GC周期如下所示:
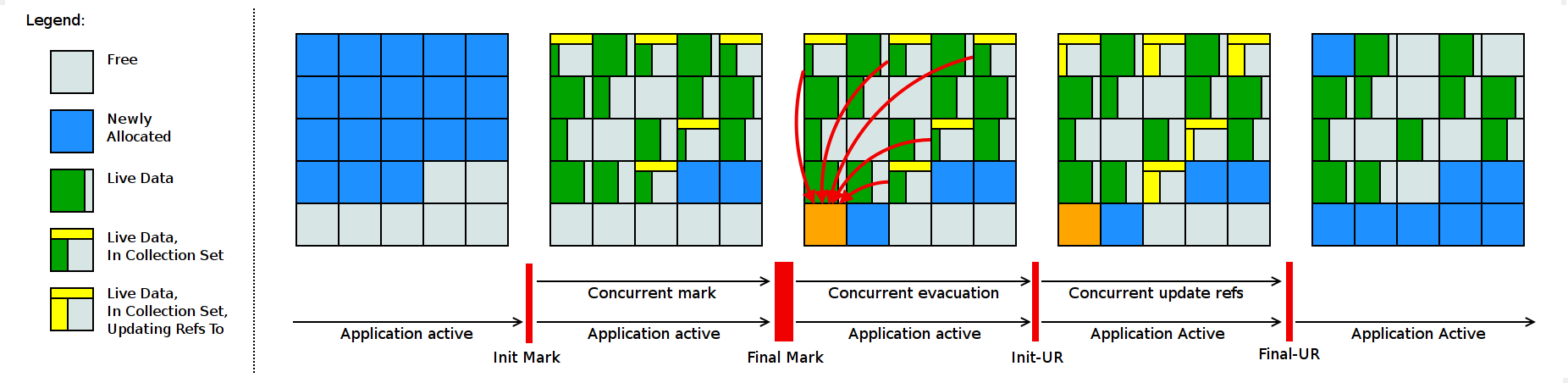
1 | GC(3) Pause Init Mark 0.771ms |
上面的阶段大致如下:
- Init Mark(初始标记) :启动并发标记。为并发标记阶段准备堆和应用程序线程,然后扫描根集。这是周期中第一次停顿,主要是对根集的扫描消耗时间。因此,停顿持续时间取决于根集大小。
- Concurrent Marking(并发标记) :遍历堆,并追踪可达对象。此阶段与应用程序一起运行,其持续时间取决于堆中存活对象的数量和对象图的结构。由于应用程序可以在此阶段自由分配新数据,因此在并发标记期间堆占用率会上升。
- Final Mark(最终标记) :通过排空所有挂起的标记/更新队列并重新扫描根集来完成并发标记。它还通过确定要疏散的region(collection set),预先疏散一些根来初始化疏散,并且通常为下一阶段准备运行时间。这项工作的一部分可以在Concurrent precleaning (并发预清理)阶段并发完成。这是周期中的第二次停顿,最主要的时间消耗方是排空队列和扫描根集的过程。
- Concurrent Cleanup(并发清理) :回收当前垃圾region——即在并发标记之后检测到的没有存活对象的region。
- Concurrent Evacuation(并发疏散) :将对象从collection set复制到其他region。这是与其他OpenJDK GC的主要区别。此阶段再次与应用程序一起运行,因此应用程序可以自由分配。其持续时间取决于该GC周期选择的collection set的大小。
- Init Update Refs(初始更新引用) :初始化更新引用阶段。除了确保所有GC和应用程序线程都已完成疏散,然后为下一阶段准备GC之外,它几乎没有任何作用。这是周期中的第三次停顿,也是最短的停顿。
- Concurrent Update References(并发更新引用) :遍历堆,并更新对并发疏散极端移动对象的引用。 这是与其他OpenJDK GC的主要区别。它的持续时间取决于堆中的对象数,但不取决于对象图结构,因为它会线性扫描堆。此阶段与应用程序同时运行。
- Final Update Refs(最终更新引用) :通过重新更新现有根集来完成更新引用阶段。它还从collection set中回收region,因为现在堆没有对它们的(陈旧)对象的引用。这是周期中的最后一次停顿,其持续时间取决于根集的大小。
- Concurrent Cleanup(并发清理):回收collection set region,这些region当前没有引用。
性能指南和诊断
总体思路
Heap sizes(堆大小): 与几乎所有其他GC的性能一样,Shenandoah性能取决于堆大小。当有足够的堆空间能够满足并发阶段运行(参见下面的”Failure Modes(失败模式)”部分)时的分配时,它应该能够更好地运行。并发阶段的时间与live data set (LDS)的大小——live data占用的空间——相关。因此,合理的堆大小取决于LDS和工作负载中的分配压力:对于给定的分配速率,较大的LDS需要同比例的较大的堆大小;对于给定的LDS,较大的分配率需要较大的堆大小。对于那些具有很小live data set和适度分配压力的工作负载,1~2GB的堆就表现得不错了。我们通常在各种工作负载上测试4~128GB的堆,其中LDS大小最高达到80%。不要害羞地尝试不同的堆大小来适配你的工作负载。
Pauses(停顿): Shenandoah的停顿行为主要由根集操作主导:扫描和更新根。根集包括:局部变量,嵌入在生成的代码中的引用,interned Strings,类加载器的引用(例如,static final引用),JNI引用,JVMTI引用。拥有更大的根集通常意味着使用Shenandoah会有更长的停顿,除非具体的JDK版本具有同时执行部分工作的能力,并且Shenandoah能够使用它。二阶效应是:a)弱引用处理(在Final Mark(最终标记)阶段中发生),但仅适用于那些需要处理的引用; b)类的卸载和其他JDK清理(也会在Final Mark(最终标记)阶段时发生)。通过配置控制处理频率(包括完全禁用它)的其他选项和/或修改应用程序以更好地发挥作用,可以减轻这些二阶效应。
Throughput(吞吐量): 由于Shenandoah是并发GC,它在收集周期中使用屏障来维护不变量。这些屏障可能会导致可测量的吞吐量损失。请参阅下面的诊断部分,了解如何剖析那里发生的事情。 一些用户报告说,通过自然地将并发GC工作卸载到备用和其他空闲核心,使由于屏障导致的吞吐量损失得到了弥补;换句话说,在某些情况下,它会提高应用程序+JVM利用率以获得更高的应用程序吞吐量。
在大多数情况下,停顿时间在0~10ms之内,吞吐量损失在0~15%之内。实际性能数据在很大程度上取决于实际应用,负载文件等。对于没有大量根,弱引用和/或class churn的应用程序,停顿可以在亚毫秒范围内。对于不会使堆变异很多,或者当前编译器对其进行了很好的优化的应用程序,屏障开销可能接近于零。本节的其余部分描述了使用Shenandoah测试和诊断性能行为的方法。如果您怀疑具体用例有什么问题,请告知开发人员。有可能,这是一个可管理的issue或直接的bug。
基本配置
基本配置和命令行选项:
- -Xlog:gc (since JDK 9) or -verbose:gc (up to JDK 8):打印单独的GC计时
- -Xlog:gc+ergo (since JDK 9) or -XX:+PrintGCDetails (up to JDK 8):打印heuristics 决策,如果有异常值的话,打印异常值。
- -Xlog:gc+stats (since JDK 9) or -verbose:gc (up to JDK 8) :在运行结束时,在Shenandoah内部计时上打印汇总表。
在启用日志记录的情况下运行几乎总是一个好主意。该汇总表传达了有关GC性能的重要信息,我们几乎不可避免地要求在性能错误报告中提供一个。Heuristics 日志对于确定GC异常值非常有用。
其他推荐的JVM选项包括:
- -XX:+AlwaysPreTouch:将堆页面提交到内存中以减少latency hiccups。
- -Xmx == -Xms :使堆不可调整大小可以减少堆管理时的hiccups。对于Shenandoah,-Xms与其他收集器的相关性较低,因为它只将其视为“初始”堆大小(这可能在将来发生变化)。但是,与AlwaysPreTouch相结合,-Xmx == -Xms会在启动时提交所有内存,这可以避免在最终使用内存后出现hiccups。
- -XX:+UseTransparentHugePages: 这大大提高了大堆的性能。建议在Linux上将/sys/kernel/mm/transparent_hugepage/enabled和/sys/kernel/mm/transparent_hugepage/defrag设置为“madvise”。使用AlwaysPreTouch运行时,init/shutdown会更快,因为它将使用更大的页面进行预处理。它还将在启动时预先支付碎片整理成本。
- -XX:+UseNUMA:虽然Shenandoah尚未明确支持NUMA,但最好启用此功能以在多插槽主机上启用NUMA交叉存取。与AlwaysPreTouch相结合,它提供了比默认的开箱即用配置更好的性能。
- -XX:-UseBiasedLocking:在无竞争(偏向)锁定吞吐量与JVM根据需要启用和禁用它们的安全点之间存在权衡。对于面向延迟的工作负载,可以关闭偏向锁定。
- -XX:+DisableExplicitGC:从用户代码调用System.gc()强制Shenandoah执行STW Full GC,这对GC停顿不利;禁用此选项可以防止库执行此操作。还有一个替代 -XX:+ExplicitGCInvokesConcurrent,可以在System.gc()上强制并发循环而不是Full GC,建议您在System.gc()调用确实必要的情况下使用它。
Heuristics启发式方法
Heuristics判断Shenandoah何时启动GC周期,以及它认为的该疏散的region。可以使用-XX:ShenandoahGCHeuristics =
adaptive (default) 此启发式方法通过观察以前的GC周期,尝试启动下一个GC周期,以便在堆耗尽之前完成操作。
a. -XX:ShenandoahInitFreeThreshold=#: 触发”learning”集合的初始阈值。
b. -XX:ShenandoahMinFreeThreshold=# :heuristics无条件触发GC的可用空间阈值。
c. -XX:ShenandoahAllocSpikeFactor=#:要预留多少堆来承担分配峰值。
d. -XX:ShenandoahGarbageThreshold=#:设置region在标记为可收集之前需要包含的垃圾百分比。
static 此启发式决定基于堆占用和分配压力启动GC周期。该启发式配置选项如下:
a. -XX:ShenandoahFreeThreshold=#:设置启动GC周期时的空闲堆的百分比
b. -XX:ShenandoahAllocationThreshold=#:在新GC周期开始之前,设置自上一个GC周期以来分配的内存百分比。
c. -XX:ShenandoahGarbageThreshold=#:设置region在标记为collection之前需要包含的垃圾百分比。
compact 该启发式连续运行GC周期,只要分配发生,就在上一个周期结束后立即开始下一个周期。这种启发式方法通常会产生吞吐量开销,但能提供最快速的空间回收。配置选项:
a. -XX:ConcGCThreads=#:减少并发GC线程的数量,以便为应用程序运行腾出更多空间。
b. -XX:ShenandoahAllocationThreshold=#:在启动另一个周期之前,设置自上一个GC周期以来分配的内存百分比。
passive 这种启发式方法告诉GC完全被动。一旦可用内存耗尽,将触发Full Stop-The-World GC。这种启发式方法用于功能测试,但有时它可用于将GC屏障的性能异常等分(见下文),或计算应用程序中的实际live data size。
aggressive 这种启发式方法告诉GC完全活跃。它将在前一个GC周期结束后立即启动新的GC周期(如“compact”),并且疏散所有存活对象。这种启发式方法对收集器本身的功能测试很有用。它会导致严重的性能损失。
在某些周期中,Update References阶段与Concurrent Marking阶段合并,通过启发式方法裁决。可以使用-XX:ShenandoahUpdateRefsEarly=[on|off]强制启用/禁用Update References 。
失败模式
像Shenandoah这样的并发GC隐含地依赖于收集速度比应用程序分配速度更快。如果分配压力很高,并且在GC运行时没有足够的空间来分配,则最终会发生 Allocation Failure 。Shenandoah有一个优雅的降级阶梯,有助于在这些情况下幸存下来。阶梯包括:
- Pacing (-XX:+ShenandoahPacing, enabled by default).当GC运行时,它知道需要完成多少GC工作,以及有多少可用空间可供应用程序使用。当GC进度不够快时,pacer会尝试停止分配线程。在正常情况下,GC收集的速度比应用程序分配的速度快,pacer自然不会停止。注意,pacing会引入通常分析工具中不可见的本地per-thread延迟。这就是为什么停止不是无限期的,它们受-XX:ShenandoahPacingMaxDelay=#ms的限制。在最大延时到期后,无论如何都会发生分配。大多数时候,轻度分配的峰值会被pacer吸收。当分配压力非常高时,pacer将无法应对,并且降级将进入下一步。
Usual latency induced: <10 ms - Degenerated GC (-XX:+ShenandoahDegeneratedGC, enabled by default). 如果应用程序遇到分配失败,Shenandoah将陷入 stop-the-world 停顿,停止整个应用程序,并在停顿下继续GC周期。Degenerated GC 在stop-the-world 的情况下继续正在进行的“并发”周期。在许多情况下,分配失败发生在已完成大量GC工作、只剩一小部分GC工作等待完成之后,这就是STW停顿通常不大的原因。它将在GC日志、所有常见的监视和心跳线程中打印 GC pause:实际上,引发STW停顿的原因之一是使并发模式的失败可以清楚地被观察到。如果GC周期开始得太晚,或者发生了非常显着的分配峰值,将导致Degenerated GC。退化周期可能比并发周期更快,因为它不会与应用程序竞争资源,而且它使用-XX:ParallelGCThreads,而不是-XX:ConcCGThreads调整线程池大小。
Usual latency induced: <100 ms, but can be more, depending on the degeneration point - Full GC.如果没有任何帮助,例如当Degenerated GC没有释放足够的内存时,将产生Full GC,并最大化地对堆进行整理。某些场景,比如异常碎片化的堆,以及实现性能bug和overlook,只能由Full GC修复。如果至少有一些内存可用,这个最后阶段的GC能够保证应用程序不会因OOM而失败。
Usual latency induced: >100 ms, but can be more, especially on a very occupied heap
除了可以打印单个Degenerated GC和Full GC事件的常用GC日志之外,-Xlog:gc + stats将在运行结束时显示如下内容:
1 | Under allocation pressure, concurrent cycles may cancel, and either continue cycle |
从这一点来看,如果应用程序遇到以下任何一个降级步骤,可以尝试以下操作:
- 为应用程序提供更多堆。满足在GC运行时更多的分配要求。
- 减少堆中的live data量。使GC周期更快地运行,并更好地应对分配。
- 削减分配压力。例如,减少分配线程的数量,或修复应用程序中的主要allocation hogs。
- 调整启发式算法,尽快启动GC周期。如果GC日志已经说GC正在运行连续周期,那么该项操作可能没什么用。
- 加快pacing延迟。这将导致更多的线程分配停滞,而不是升级到Degenerated和Full GC——注意,这仍然会给分配线程带来延迟!
性能分析
性能分析方法:
一些奇怪的性能行为——如分配失败GC或耗时的最终标记——可以通过heuristics issues解释,你可以使用-Xlog:gc + ergo配置。如果你有长时间运行的工作负载,在Shenandoah Visualizer下运行可以让你理解高级GC行为,有时类似奇怪的行为在SV下很明显。
一些性能差异可以用Shenandoah下更大的分配压力解释,因为它包含每个对象的转发指针。查看分配率以确定其是否有问题,并可以通过实验进一步证实(例如,增强对象可以减少与其他收集器之间的性能差异)。在某些情况下,较大的内存占用意味着退出CPU cache,寻找L1/L2/LLC遗漏的差异。
许多吞吐量差异可以用GC屏障开销来解释。当使用-XX:ShenandoahGCHeuristics=passive运行时,这是启发式方法独有的,正确性不需要障碍,因此启发式方法禁用它们。然后可以有选择地启用屏障,并查看哪些屏障正在影响吞吐量性能。“passive”启发式禁用的障碍列表列在GC输出中,如下所示:
1
2
3
4
5
6
7
8
9
10$ java -XX:+UseShenandoahGC -XX:ShenandoahGCHeuristics=passive -Xlog:gc
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahSATBBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahKeepAliveBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahWriteBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahReadBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahStoreValReadBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahCASBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahAcmpBarrier by default
[0.002s][info][gc] Passive heuristics implies -XX:-ShenandoahCloneBarrier by default
[0.003s][info][gc] Using Shenandoah使用Linux perf可以轻松分析本机GC代码:
Build OpenJDK with –with-native-debug-symbols=internal, this will get you the mapping to C++ code
Run the workload with perf record java … (plain profile) or perf record -g java … (call tree profile)
Open the report with perf report
Navigate the report, and see where are suspiciously hot methods/paths are. Pressing “a”on the method usually gives a more detailed disassembly for it
分析障碍代码需要启用PrintAssembly的构建。我们建议使用JMH -prof perfasm创建隔离的场景并查看Shenandoah下生成的代码。
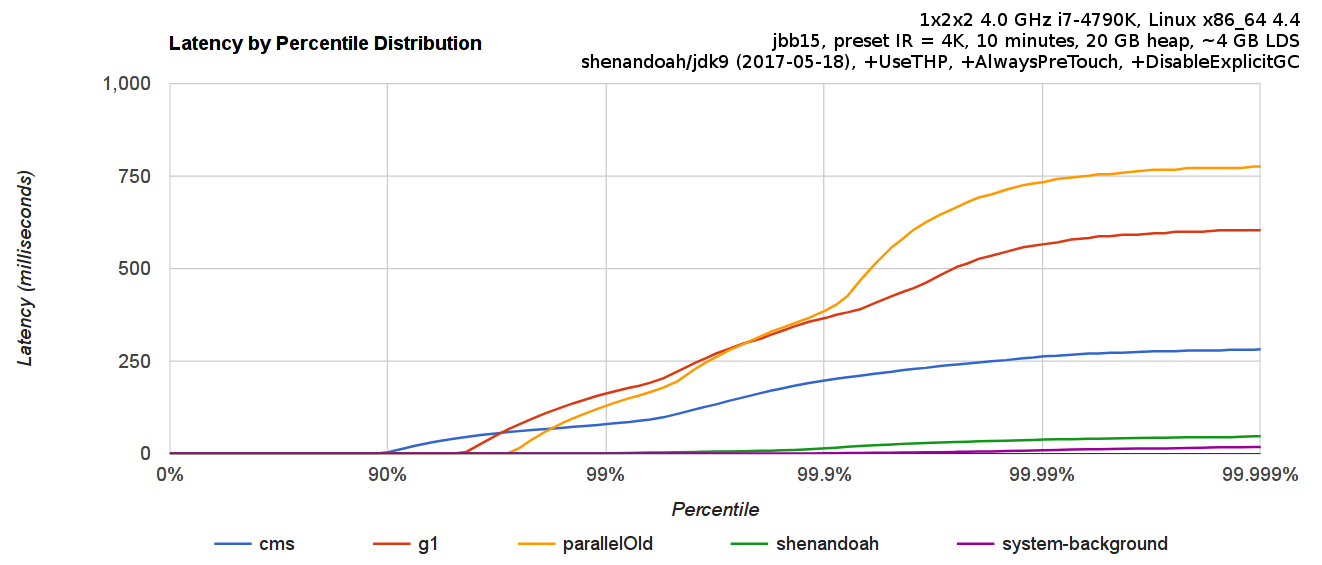
重要的是要明确GC停顿可能不是常规应用程序中响应时间的唯一重要来源。具有较大的GC停顿时间很快就会出现响应时间问题,但缺少长时间的GC停顿并不总是意味着良好的响应时间。排队延迟、网络延迟、其他服务延迟、OS调度程序抖动等都可能是影响因素。建议使用响应时间度量来运行Shenandoah,以全面了解系统中正在发生的事情,然后可以将其与GC停顿时间统计数据关联起来。
例如,这是一个带有jHiccup其中一个工作负载的示例报告:
功能诊断
本节介绍了可以诊断和/或调试Shenandoah的方法。
以下是缩小问题范围的步骤:
- 使用 -XX:+ShenandoahVerify运行。这是针对GC bug的第一道防线,它在release和fastdebug构建中都可用。如果Verifier识别出一个问题,那么它很可能是GC bug。为了更好地诊断这一点,一个简单的复制器将是很方便的。在许多情况下,GC之前发生的事情很重要,例如GC所采取的最后操作。该历史记录通常记录在关联的hs_err_pidXXXX日志中,确保在报告bug时将其包含在内。
- 使用fastdebug build运行。在许多情况下,这将产生有意义的断言消息,指向GC检测到功能异常的最早时刻,而Shenandoah断言很多。这些构建可以通过添加–enable-debug来配置和重新构建生成。像往常一样,hs_err_pidXXXX.log方便地记录了有助于调查断言失败的环境和历史数据。
- 使用-XX:ShenandoahGCHeuristics=passive运行,它将仅执行stop-the-world GC,并避免执行大多数并发工作。如果问题在passive模式下消失,那么它一定是并发阶段和/或屏障中的bug。
- 使用不同的编译器运行:-Xint(仅限解释器),-XX:TieredStopAtLevel=1(仅限C1),-XX:-TieredCompilation(仅限解释器和C2)——剖析哪些模式失败,哪些没有。这将突出显示问题是在解释器、C1或C2中的屏障处理或优化。这通常有助于与fastdebug build相结合,因为编译器也会产生断言。
- 使用-XX:ShenandoahGCHeuristics=aggressive运行。这种启发式方法连续运行GC,并疏散所有非空region。由于Shenandoah并发执行大多数GC繁重工作,所以这不会阻止应用程序的执行,尽管在这种模式下GC将消耗更多的周期并降低应用程序的运行速度。注意,此模式下启用Verifier可能会将性能降低到不实用的水平。
- 使用-XX:+ShenandoahVerifyOptoBarriers(验证C2理想图中的屏障),-XX:VerifyStrictOopOperations(执行额外的检查来验证oop比较是否正确)添加更多验证。
适用于Shenandoah的一般调试技术:
- 在代码中围绕失败的断言放置日志语句,以便更好地理解问题。有了足够的日志记录,你就可以重新跟踪收集器中发生的所有事情。
- 在代码中可疑的部分周围添加更多的断言。查看shenandoahassert中的宏定义。hpp查看rich断言的可用性
- 附加一个本机调试器,例如gdb,通过请求VM在失败时使用-XX:OnError=”gdb - %p”执行外部操作(将%p替换为进程PID)
- 创建一个简单的复制器并交给Shenandoah开发人员。:)
构建,下载,安装,运行
自12以来,Shenandoah就在主线JDK中进行开发。除了主线构建之外,还有一些下游的构建可用于当前JDK。开发repos和builds之间的变更流程如下面的简化图所示。
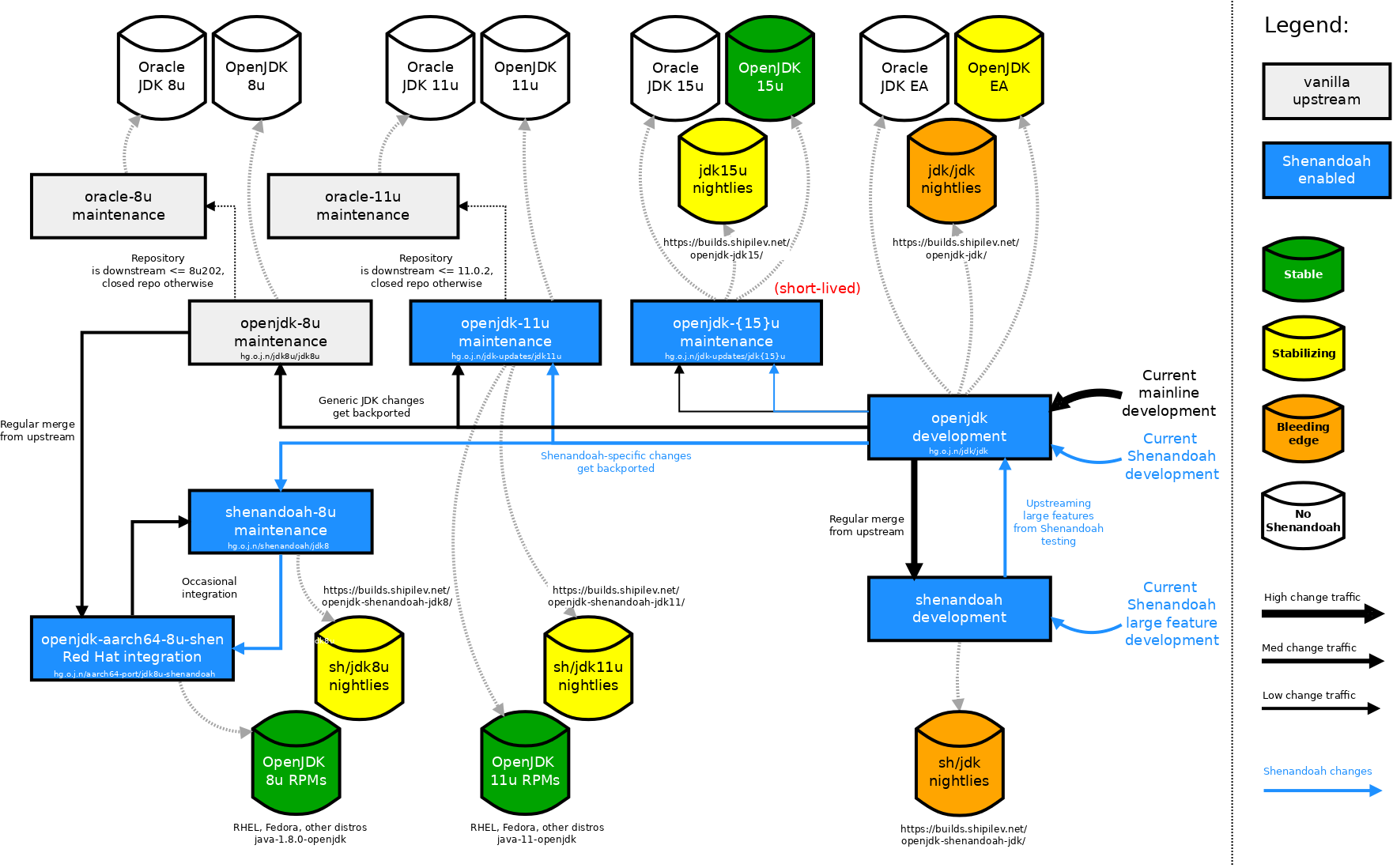
如果你是早期采用者,尝试前沿构建应该在性能方面更有利可图,但可能会冒险暴露于尚未发现的bug。如果希望在实际部署中运行Shenandoah,则首选使用最稳定的版本。